on
Meet bitbucket-exporter
Since early summer last year I’ve been working on a small hobby project in Rust. I recently reached a level of functionality where it might be useful to someone so I wanted to write a few words about the project.
The technical motivation
For the last four or five years, with the introduction of lambdas, streams and an optional type to the Java language I’ve been seeing a shift towards adopting a more functional style when writing Java code. I have been trying to embrace this myself as much as possible when writing new code.
Between this and the input I get through my Twitter echo chamber, I’ve been getting very curious about the benefits of immutable types, avoiding nulls, using a rich type system to make certain types of failure difficult to trip over and the benefits of writing code with a functional style, and most of all writing in a language where this style of coding is idiomatic.
During the same time period there have been a lot of languages that have risen in popularity. One of these is Rust which seems to have all of the concepts I’m interested in and I’ve been thinking for a while that I should have a little hobby project through which I can experiment with the language.
The functional motivation
On some of the more successful projects I’ve worked on in the past there has been a high focus on closing open pull requests as quickly as possible. The main benefits of this are two-fold;
- If there is a large period of time between the code is written and the time it is reviewed, the developer will have a more significant context switch when it comes time to respond to the comments. If feedback is received while the original thought processes are still fresh in memory the whole process will likely feel like less of a burden.
- Code waiting to be reviewed is finshed code that hasn’t been shipped. There’s greater value in shipping the finished work than starting on something new.
With this as a goal I wanted to create a dashboard to visualise the state-of-play on my current project. Like many organisations on the Atlassian stack we utilise BitBucket Server from Atlassian for source control, and like many that have made the move to OpenShift we use Grafana with Prometheus as a datasource for all monitoring, therefore I needed a tool to get metrics about pull requests from BitBucket Server into Prometheus.
A metrics exporter
In the general case, when you have an application that you wish to monitor with Prometheus you will expose an HTTP endpoint that returns Prometheus formatted metrics that is then scraped by Prometheus at a regular interval. While BitBucket Server does have a plugin mechanism that could be used to provide such an endpoint I do not have the necessary access to install my own plugins and we do not have a test instance I could play around with without potentially affecting the entire organisation.
For this kind of situation, where it is not feasible to modify the system you wish to monitor to expose a Prometheus endpoint directly, but there are other methods to get at the data you wish to expose, it is common to run what is called an exporter.
An exporter is a process, seperate from the application being monitored, that can query the system for the relevant data and present this data via the necessary HTTP endpoint for Prometheus to ingest the data.
Writing a small application to poll BitBucket Server’s APIs for metrics about pull requests, exposing these via an HTTP endpoint, and visualising these on a Grafana dashboard sounded like a well defined, managable scope for my first experience with Rust.
The result
Over the Christmas holiday I finally got around to implementing support for iterating over multiple pages in the results from BitBucket Server and now feel that I can call this version 1. It iterates over all repositories in all projects and counts the number of open pull requests. These counts are exposed in the Prometheus format as gauges.
The code is available in a repository in gitlab, and there is a docker image available in the repository there. I’m happy to receive feedback if you have it.
I threw together a quick example dashboard that shows the sum of open pull requests per project and per repository with a variable that can be used to drill down on a specific project or set of projects.
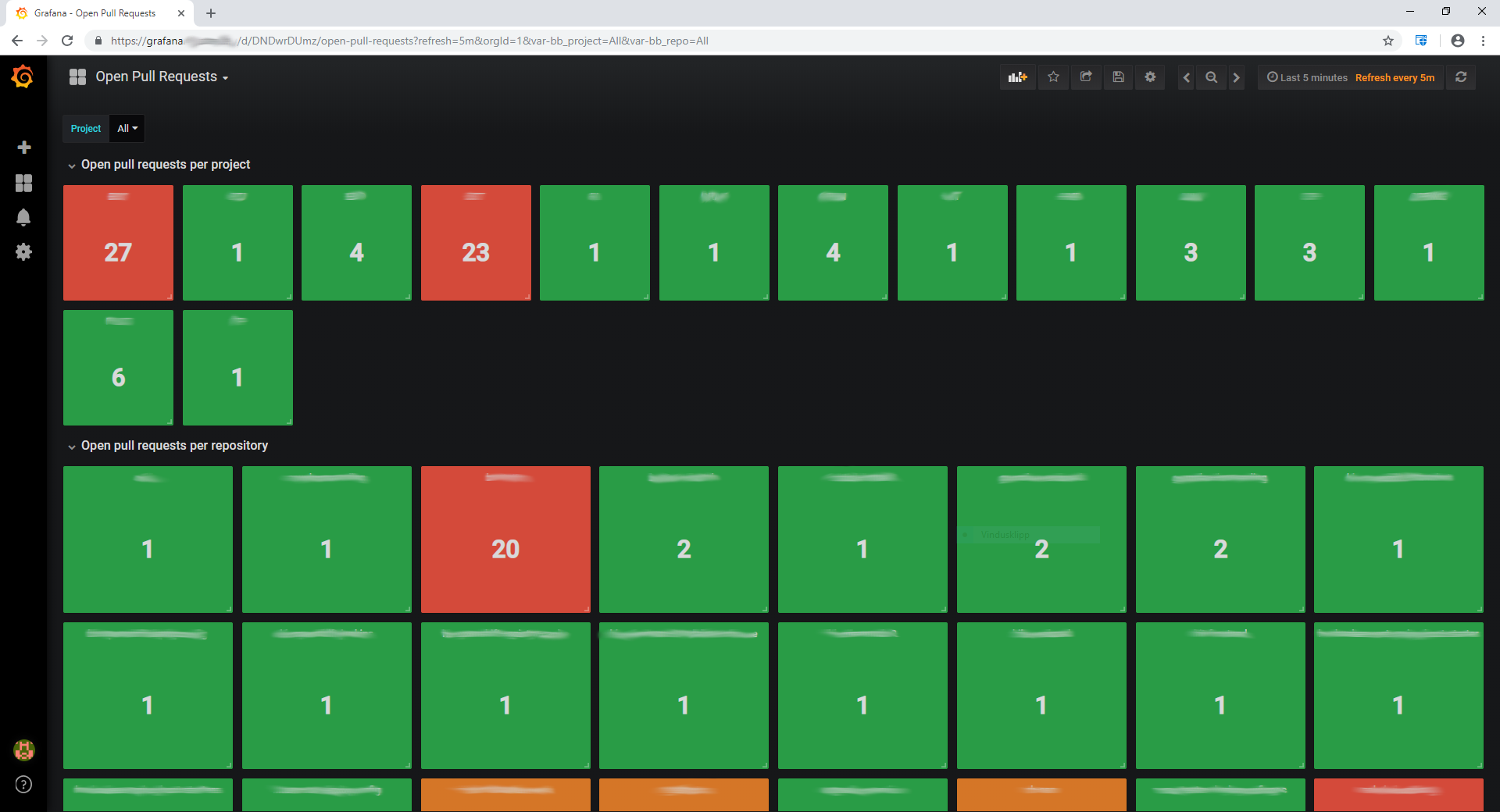 Dashboard showing all open pull requests across all projects in BitBucket
Dashboard showing all open pull requests across all projects in BitBucket
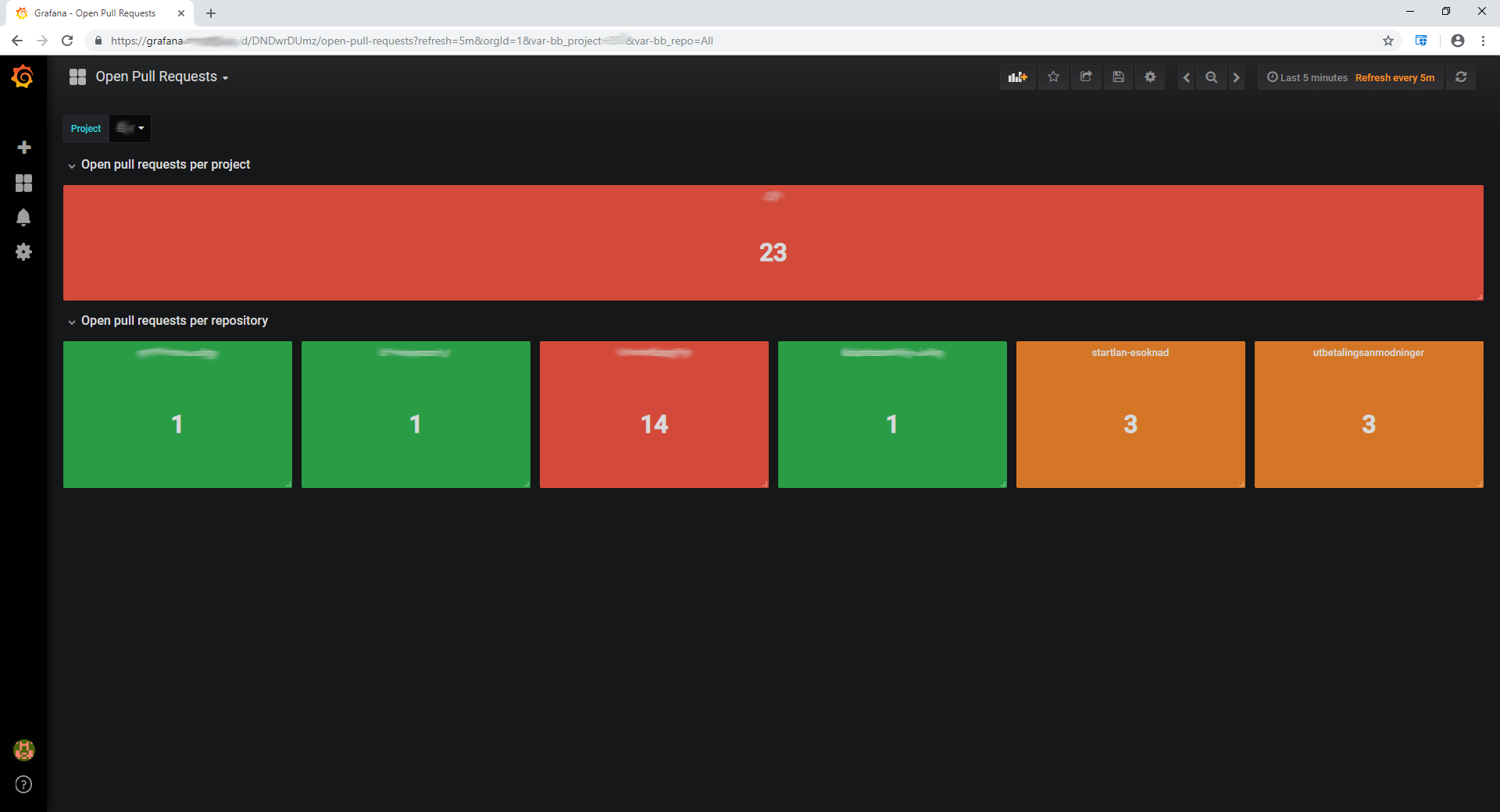 Dashboard drilled down on a single BitBucket project
Dashboard drilled down on a single BitBucket project
Future plans
Now that I’ve written about it, my intention is to put this project to the side for a while so that I can start on something new. However, if there is interest, my priorities can easily be changed. Obvious things that might be interesting to add are;
- Age of oldest pull request per repository. This goes back to the core of my initial motivations to reduce the amount of time pull requests are left open.
- Number of merged and declined pull requests.
- Number of branches with and without associated pull requests. Using this you could visualise work currently in progress.
It might also be interesting to experiment with counters triggered by webhooks instead of gauges populated by polling, but from what I can determine from a quick google, this would be dependent upon remembering to configure the webhook per repository, the current strategy is relatively failsafe as long as the user has the necessary read access to all repositories.
There are also some technical improvements and learning opportunities documented in the project’s README file.